目前消息中间件产品比较多了,之前使用的都是阿里的rocketmq.最近阿里云新上线了kafka,于是我做了相关调研,是否需要更换。
我们先来看看相同点:
高吞吐量
两个mq都是通过日志的形式实现消息的持久化,同时rocketmq也支持同步刷盘,提高单机可靠性。
高可用
两个mq都支持同步和异步replica。
rocketmq:master-slaver主备同步。
kafka:较为复杂,实质上是通过partition多follower的方式冗余。
高度负载均衡
发送负载均衡,消费负载均衡
消息消费实时性
rocketmq:长轮询
kafka:之前是短轮询,0.8版本之后支持长轮询
ps:为什么都是长轮询,而不是push?因为消息的消费速度不确定,采用长轮询的方式,可以让消费者控制消息的获取速度。如果用push,可能会出现消费者消费速度较慢mq就将新的消息推送过来的场景。
但同时,由于架构不同,两个mq也是有比较大的区别,下面一一讲起:
kafka架构
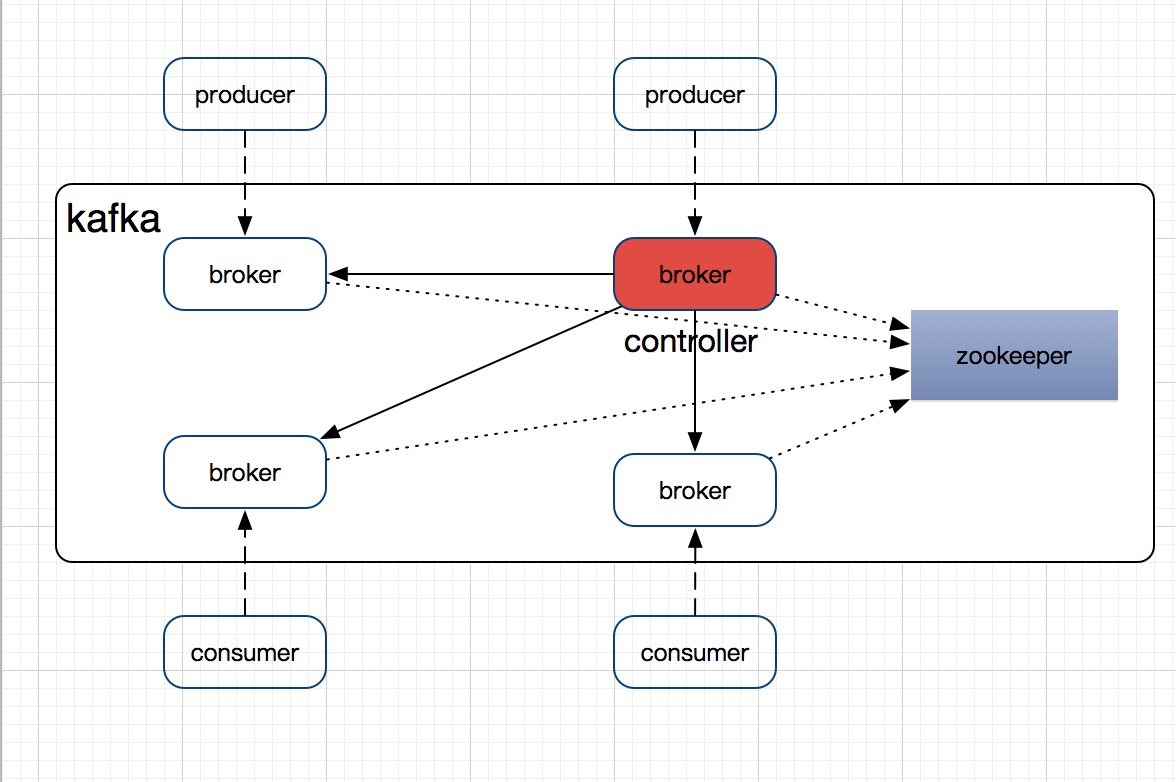
zookeeper: 整个消息服务可用性的保障,存储消息服务中的所有topic以及partition的leader-follower的关系。
controller: kafka的partition存在leader-follower即主备的关系。初期是靠zk来选举,但后续发现随着partition数量的增加,导致zk的竞争非常激烈。不得已,kafka做了一个升级,加入了controller角色。 当服务启动时,zookeepr只需要竞选出一个broker作为controller,controller来指定partition的leader-follower关系,并将相应的信息存储到zk中。
broker: 普通的消息服务器,内部有多个partition,可能会升级为controller。
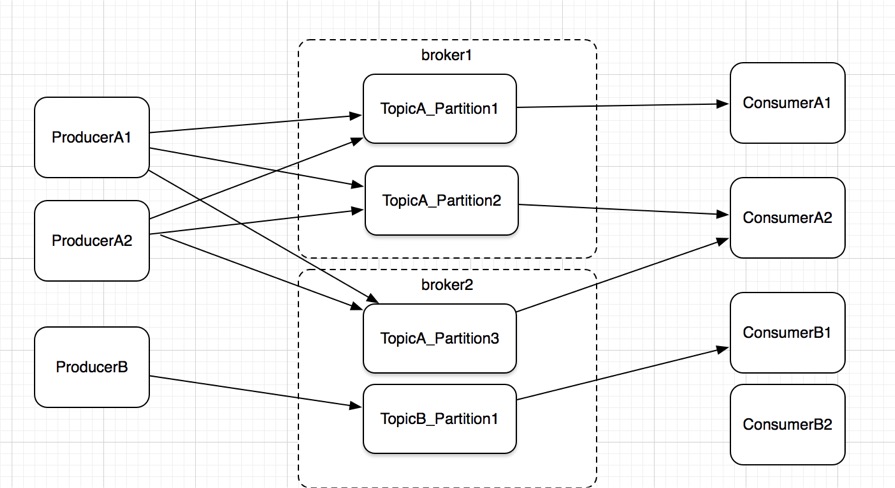
在kafka中,一个topic会被拆分成多个partition实现负载均衡,这些parition就被controller分配到多个broker中(多对多关系),每一个broker中的parition,都对于一个日志文件(加入一个broker中有不同topic的5个paritition,则有5个partition文件),这个文件相互隔离,互不干扰。
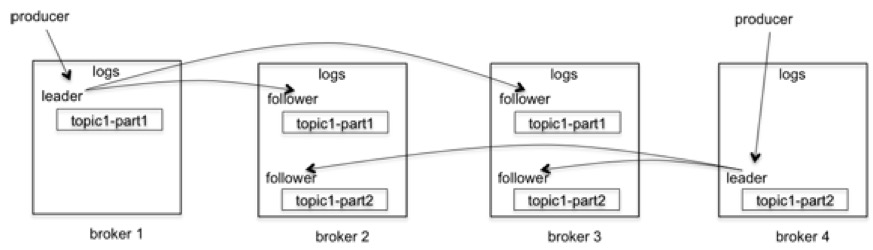
同时,每个partition会有多个replica,通过controller来指定leader-follower的关系。
producer在发送消息时,根据策略指定partition或者随机或者其它策略选择partition发送。consumer根据数量是一对一消费还是一个consumer消费多个partition(同一topic)情况下。需要主要的是,一个partition同时只能被一个consumer消费,因此如果consumer的数量大于partition的数量,那么是会有consumer收不到消息。
每个partition对应一个write offset和read offset,日志顺序写入,提高消息吞吐率。consumer顺序读消息,通过不同的策略移动read offset(比如获取消息就更新offset,或者commit消费成功之后再移动),即使consumer挂掉,新的也会沿着上次的offset读取消息。
rocketmq架构
再看下rocketmq的基本架构图:
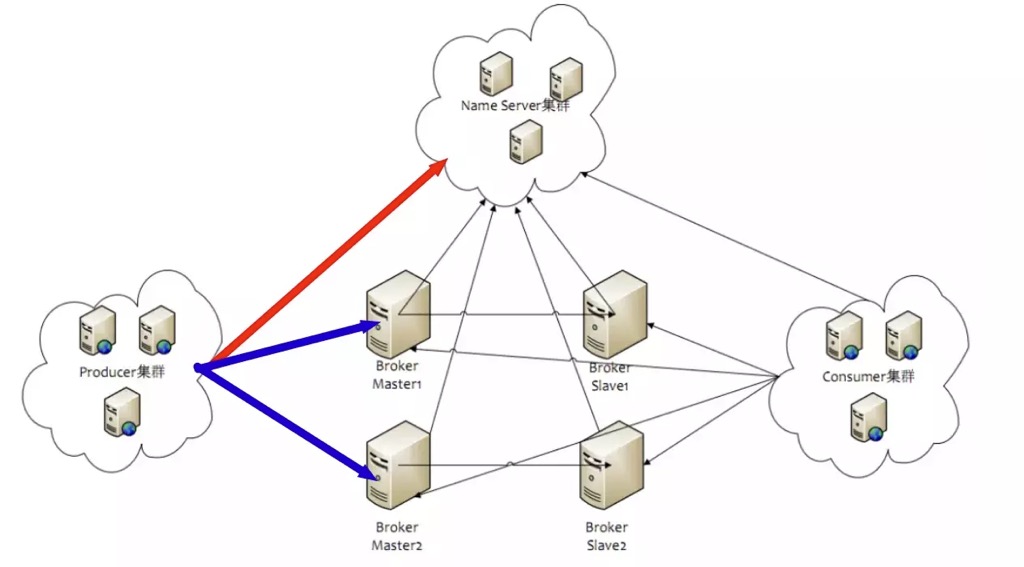
介绍一个这几个角色
name server: rocketmq自己实现的一套服务发现和注册服务,每个nameserver的机器互相不会通信,但每个服务器都会和nameserver通信。
master-slaver:主备服务器,一个master可能对应多个slaver。producer和consumer都通过nameserver找到相应的master工作,当master挂掉之后,consumer只可以从slaver读消息,producer不能再向master写消息,但会通过负载找寻其它可以写入的master。 master和slaver的服务器是初始配置好的,不会由于宕机而动态切换。
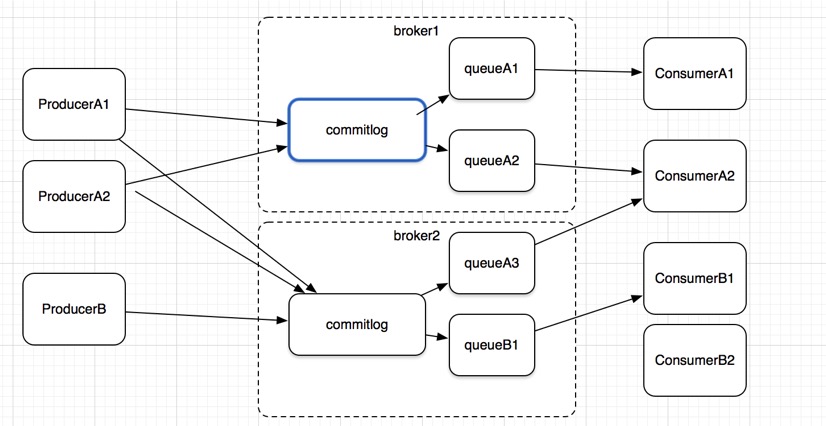
rocketmq的producer也是通过各种策略将消息分发到不同的服务器中,但与kafka不同的是,rocketmq的每个服务器上,都只有一个日志文件,叫做commitlog,多个topic的消息会同时写入到一个commitlog中。那么它是怎么做到区分不同消息的呢?这就需要一个新的模块:consume queue。
发送消息时,会在消息中注明是哪个topic。写入日志时,broker中的所有topic顺序写入commitlog,但会基于配置分化出不同的consumer queue,每个queue对应一个read offset,剩下的就和kafka相同了。
如果queue较多,这不还是随机读取了吗?rocketmq 使用pagecache技术,类似于计算机系统的swapcache来解决这个问题,多个queue对应多个cache区间,所以rocketmq的使用时要多占用一些内存的。
对比总结
通过上面的论述就可以发现问题,理论上,kafka的吞吐量峰值会更高,因为在日志刷盘时,kafka是同时写入多个文件,假如服务器有多个硬盘,会有多套IO可以并发刷盘,而rocketmq只有单个。同时,kafka的极限可靠性也比rocketmq强,单说broker,不考虑负载的情况下,即使broker只剩下一台,kafka依然可以保障运行,但rocketmq的master全部挂掉之后producer就无法写入消息来,只能人工介入。
但rocketmq同样有优势,第一就是架构简单,没有重型的zookeeper和选举策略,也没有controller这种控制角色,所有的信息更多的是基于配置的形式完成,虽然没有那么自动,但后期的维护和迭代升级也会更方便,未知的和不确定性的性能瓶颈会更少。
kafka是基于日志系统诞生的产品,关注的是高吞吐量,而rocketmq是阿里在电商和更多复杂业务中孕育的互联网化产品,提供更多的服务功能,比如事务消息、定时消息等等,而且基于它的架构,当topic数量较大时也不会产生什么问题,但kafka就会急剧的性能下降。因为kakfa的每个parition对应一个文件,topic越多,partition越多,每个broker要并发写入的文件也会更多,达到一定阈值,自然负载就下来了。